


Our client found 74% of their purchase order transactions were missing an assigned cost code.
The burden of completing and re-classifying those transactions fell squarely on the shoulders of project managers.
By leveraging sophisticated use of natural language processing and an ensemble of machine learning models including random forests and text-based Naïve Bayes, we were able to first process and bulk categorize past financial transactions, then clean error-filled and inconsistent fields to finally label the data into consistent categories.
At 99% accuracy, this data cleansing and classification pipeline allowed project managers to bypass the data clean-up work that would previously cost them hours of tedious labor to go directly to the value-add work of analyzing expenditure patterns.
A quick primer on classification models
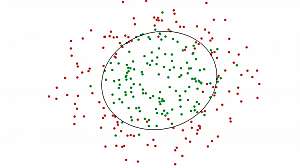
Naive Bayes is a classification technique with an assumption of independence among predictors. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
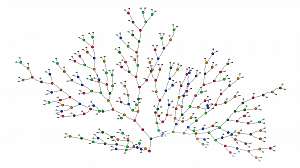
Random forest is an ensemble classifier that uses multiple models for better prediction performance. It creates many classification trees and a sample technique is used to train each tree from the set of training data.
Our work optimized spend classification, saved countless hours of manual effort and increased data consistency.
The same techniques leveraged to classify unstructured transaction data have already proven to be valuable across other areas of R&D where the presence of unstructured data was previously limiting opportunities for analytics and robust insights.
We helped our client continue their AI journey, delivering immediate value while building the framework for continual improvement in the future.
Thought Leaders
